空天地一体化网络拓扑下的数值仿真示例
使用MiniSFC进行仿真的基本流程同NS3、Mininet等其他网络仿真工具类似,即首先编写一个.py的控制脚本文件设定仿真的场景,然后使用Python运行该脚本文件,即可启动仿真。
该示例的讲解以项目中example/simple_sagintopo.py为例,介绍使用MiniSFC进行仿真时仿真脚本必要的元素,以及如何对产生的结果进行分析,完成空天地一体化网络拓扑的数值仿真。
基本工作流
编写脚本使用MiniSFC进行空天地一体化网络拓扑数值仿真的流程如图1所示:
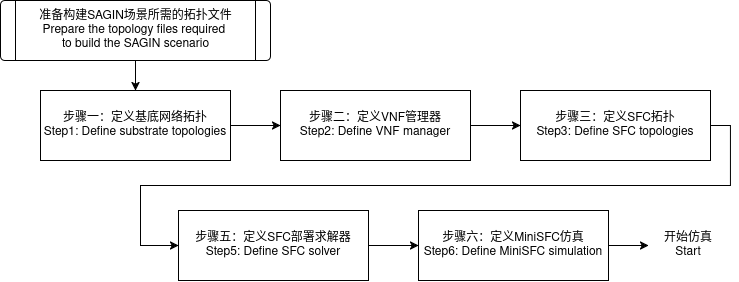
这个工作流符合构建网络仿真的直觉,即首先读取外部提供的网络拓扑,然后设置预期该网络中需要部署的服务,然后在仿真环境中模拟网络的行为。直到定义MiniSFC仿真器并开始仿真,前面的工作都可以视为准备工作。
拓扑文件
在仿真之前,需要准备一个包含所有节点和链路的网络拓扑文件,在该示例中,我们使用了路径examples/simple_sagintopo/data文件夹中的所有.json文件,作为定义网络拓扑的数据文件。
这些数据文件的获取方式如下:
使用软件
STK11生成,参考STK11 Python接口使用,生成的每个文件的命名方式为stk_data_ID_DAY_MONTH_YEAR_HOUR_MINUTE_00.000.json,包含了节点之间链路的连接关系、以及链路之间的距离。多个文件之间的关系即为随着仿真时间的推移,节点之间的连接关系会发生变化,进而导致网络拓扑发生了变化。每隔10分钟对应有一个新的文件,共有60个文件。使用我们的另外一个项目PySAGIN中的使用示例
可用于MiniSFC的SAGIN场景示例,即执行pysagin/examples/zhengzhou/下的构建脚本,生成的data文件夹中存放着以sagin_data_YEAR_MONTH_DAY_HOUR_MINUTE_00.json命名的拓扑数据文件,每个文件包含了场景中各个平台之间的连接关系信息。其内容格式与STK11生成的.json文件一致。并可以通过PySAGIN的功能对该拓扑数据进行可视化展示如下。
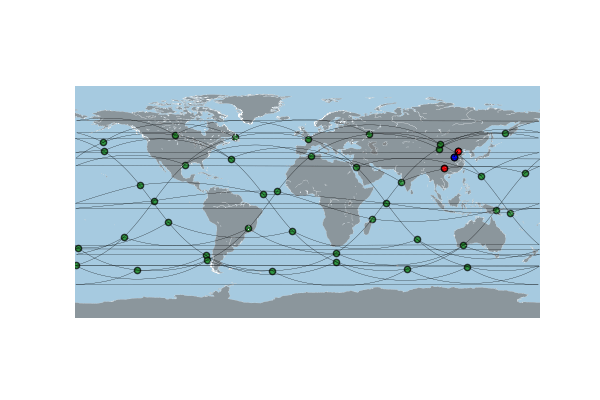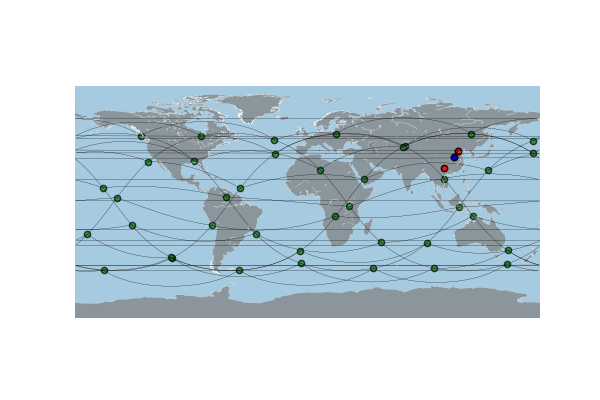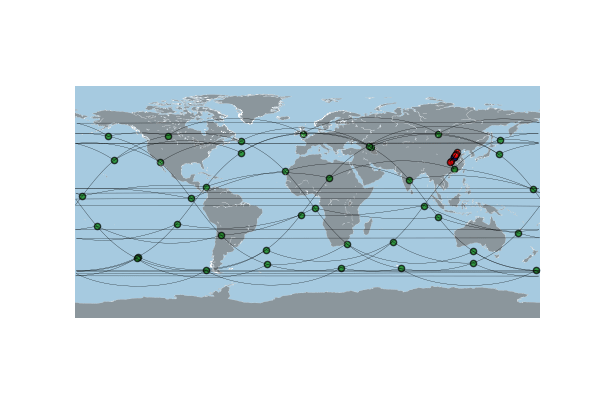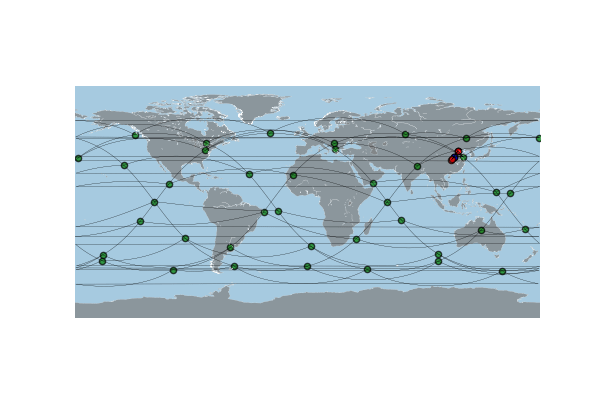
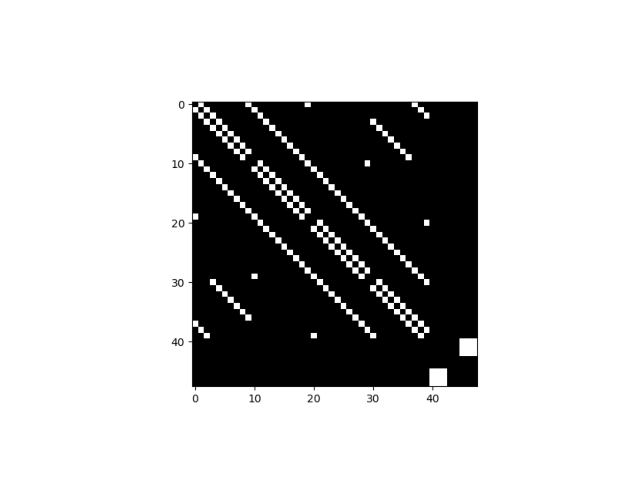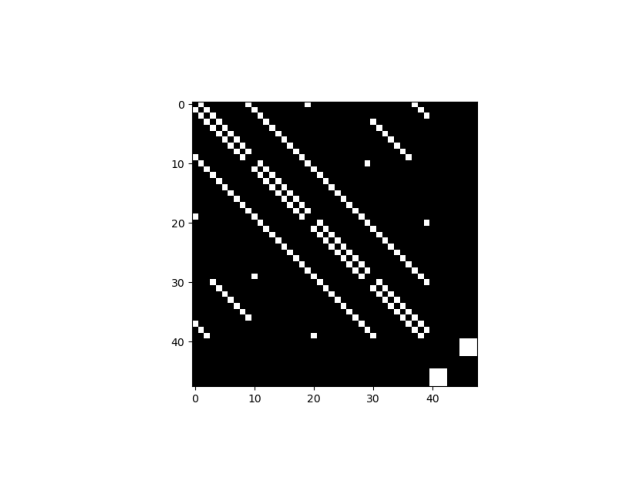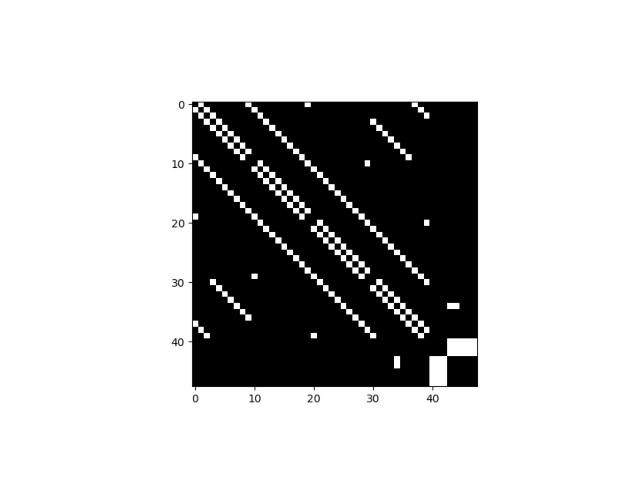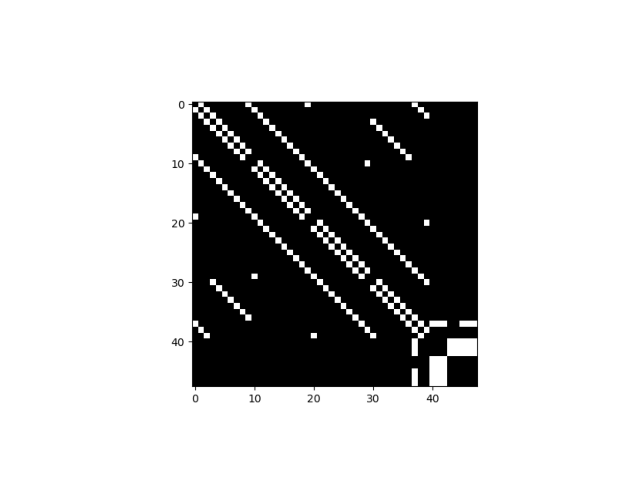
在MiniSFC中,我们提供了一个名为minisfc.util.JsonReader的模块可以实现自动化处理这些.json文件,并提取所需的拓扑数据,用于后续基底网络的构建。
准备工作
为了对每次仿真结果进行标记,MiniSFC提供了一个Trace类,该类可以记录仿真过程中产生的信息,并提供时间戳进行标记。
from minisfc.trace import Trace
SIMULATION_ID = Trace.get_time_stamp()
步骤一:定义基底网络拓扑
首先,使用数据文件中的信息构建基底网络拓扑。与前面的简单示例相同,不论如何都需要包含必要的元素才可完整定义基底网络。只不过在此示例中,无法再通过手动定义的方式来构建拓扑,而是需要使用MiniSFC提供的util包中的一系列模块来自动处理或生成数据来完成赋值。
因为在整个仿真过程中节点的数量不会发生变化,因此可以从第一个数据文件中获取节点的数量、类型等基本信息,对应于构建的空天地一体化网络的基底节点,Sat对应卫星节点标识,Base对应地面基站节点标识,Uav对应空中无人机节点标识。
from minisfc.util import NumberGen, JsonReader
jsondir = 'SSG-Json-RawData'
jsonfiles = [os.path.join(jsondir, file) for file in os.listdir(jsondir)]
jsonReader = JsonReader(jsonfiles[0])
topoNodeNames = jsonReader.all_node_list
topoNodeNum_Sat = jsonReader.sat_num
topoNodeNum_Base = jsonReader.base_num
topoNodeNum_Uav = jsonReader.uav_num
topoSize = len(topoNodeNames)
时间:一个时间序列,用于标记网络拓扑发生变化的时间点,这里采用以分钟为单位的时间戳,即从0分钟开始,每隔10分钟对应一个时间戳。MiniSFC会根据该信息来自动生成事件,标记网络拓扑此时发生了变化,并对网络进行相应的调整。
topoTimeList = list(np.arange(0.0,600.0,10.0))
邻接矩阵字典:一个以时间为索引的邻接矩阵字典,用于描述网络运行过程中不同时间点的节点之间的连接关系。矩阵的行数和列数分别为节点的数量,矩阵中的元素表示节点i和节点j之间是否存在一条链路。该字典的键需要与时间序列中的元素严格一一对应。需要注意的是该邻接矩阵需包含自环,这么做是基于部署在同一个物理设置上的不同VNF可以通过内部链路进行通信。这里直接使用
JsonReader模块的getAdjacencyMat方法来获取邻接矩阵。
topoAdjMatDict = {topoTime:JsonReader(jsonfiles[i]).getAdjacencyMat()
for i,topoTime in enumerate(topoTimeList)}
链路权重矩阵字典:一个以时间为索引的链路权重矩阵字典,用于描述网络运行过程中不同时间点的链路的权重。矩阵的行数和列数分别为节点的数量,矩阵中的元素表示节点i和节点j之间的链路的权重。该字典的键需要与时间序列中的元素严格一一对应。该权值默认为两个节点之间的传播延迟,单位为毫秒。需要注意各个权值矩阵应与邻接矩阵中的元素一一对应。即基于这样一种假设,两个节点之间不存在链路是,其权值矩阵中的元素应该为0或无穷大(因为节点的可达性是基于邻接矩阵的,因此不影响服务的时延累计的计算)。这里直接使用
JsonReader模块的getWeightMat方法来获取链路权重矩阵。
topoWeightMatDict = {topoTime:JsonReader(jsonfiles[i]).getWeightMat()
for i,topoTime in enumerate(topoTimeList)}
节点资源字典:一个以时间为索引的节点资源字典,用于描述网络运行过程中不同时间点的节点的资源信息。字典的键为元组,包含时间和资源类型两个元素,值为一个列表,包含每个节点的资源信息。资源类型可以是CPU、内存等,具体取决于想要模拟的网络的资源类型。需要注意的是,资源信息的数量应该与节点的数量相匹配,即每个节点都应该有对应的资源信息。且时间信息应该与时间序列中的元素严格一一对应。这里直接使用MiniSFC提供的
NumberGen模块的getVector方法来生成节点资源信息。
topoNodeResourceDict_cpu = {(topoTime,'cpu'):NumberGen.getVector(topoSize,**{'distribution':'uniform','dtype':'int','low':10,'high':50})
for topoTime in topoTimeList}
topoNodeResourceDict_ram = {(topoTime,'ram'):NumberGen.getVector(topoSize,**{'distribution':'uniform','dtype':'int','low':500,'high':500})*1000 # unit conversion Gb2Mb
for topoTime in topoTimeList}
topoNodeResourceDict = {**topoNodeResourceDict_cpu,**topoNodeResourceDict_ram}
链路资源字典:一个以时间为索引的链路资源字典,用于描述网络运行过程中不同时间点的链路的资源信息。字典的键为元组,包含时间和资源类型两个元素,值为一个矩阵,包含每个链路的资源信息。资源类型可以是带宽等,具体取决于想要模拟的网络的资源类型。需要注意的是,资源信息的数量应该与链路的数量相匹配,即每个链路都应该有对应的资源信息。且时间信息应该与时间序列中的元素严格一一对应。这里直接使用MiniSFC提供的
NumberGen模块的getMatrix方法来生成链路资源信息。(由于空天地一体化网络的链路的异构性,这里的链路资源信生成过程较为复杂,大致而言是区分星间链路和星地链路的生成过程,然后将两者的资源信息叠加)
topoLinkResourceMat_Sat = NumberGen.getMatrix(topoNodeNum_Sat,**{'type':'symmetric','dtype':'int','low':100,'high':1000}) # unit conversion Mb
topoLinkResourceMat_Other = NumberGen.getMatrix(len(topoNodeNames),**{'type':'symmetric','dtype':'int','low':50,'high':300}) # unit conversion Mb
topoLinkResourceMat_Other[0:topoNodeNum_Sat,0:topoNodeNum_Sat] = topoLinkResourceMat_Sat
topoLinkResourceDict = {(topoTime,'band'):topoLinkResourceMat_Other+np.eye(topoSize,dtype=int)*20*1000 for topoTime in topoTimeList} # unit conversion Gb2Mb
当这些信息准备好后,就可以构建一个来自于Minisfc的SubstrateTopo对象,该对象包含了所有网络拓扑信息。
from minisfc.topo import SubstrateTopo
substrateTopo = SubstrateTopo(topoTimeList,topoAdjMatDict,topoWeightMatDict,
topoNodeResourceDict,topoLinkResourceDict)
为了方便后续的仿真,可以将该SubstrateTopo对象保存为一个pickle文件进行固化,即无需每次都重新构建该对象,该方法适用于构建随机网络拓扑的场景并测试不同算法的性能时,进行变量控制。
with open(f"{substrateTopo.__class__.__name__}_{SIMULATION_ID}.pkl", "wb") as file:
pickle.dump(substrateTopo, file)
步骤二:定义VNF管理器
SFC所建立的服务是由多个VNF组成的,每个VNF都代表一个具体的功能,这些VNF需要部署在基底网络上,并按照一定顺序部署。MiniSFC提供了VnfManager类来管理VNF的部署和调度。因此在仿真之前,需要向VnfManager中添加VNF的模板,并设置每个VNF的资源占用信息。该过程类似于用户的服务注册环节,即用户需要向系统中事先注册自己所需的服务,进而在后续运行中,系统根据用户的需求提供相应的服务。
实例化:
VnfManager对象可以直接实例化,不需要任何参数。
from minisfc.mano.vnfm import VnfManager,VnfEm
nfvManager = VnfManager()
添加VNF模板:VNF在MiniSFC中被抽象为
VnfEm类,该类包含了VNF的ID、CPU占用、内存占用、带宽占用等信息。VnfManager对象提供了add_vnf_into_pool方法,用于向其内部的VNF模板池中添加VNF模板。需要注意的是,VNF模板的ID必须是唯一的,且不能与其他VNF模板的ID重复。'vnf_cpu'的值应该是浮点数,表示VNF的CPU占用,单位为核数。'vnf_ram'的值应该是整数,表示VNF的内存占用,单位为MB。由于空天地一体化网络的宏大场景,服务的设定也无法手动一一设置,因此需要借助MiniSFC提供的NumberGen模块来批量生成随机数进行赋值。
vnfTypeNum = 10
vnfRequstCPU = NumberGen.getVector(vnfTypeNum,**{'distribution':'uniform','dtype':'int','low':1,'high':10})
vnfRequstRAM = NumberGen.getVector(vnfTypeNum,**{'distribution':'uniform','dtype':'int','low':1,'high':10})
for i in range(vnfTypeNum):
vnfEm_template = VnfEm(**{'vnf_id':i,'vnf_cpu':vnfRequstCPU[i],'vnf_ram':vnfRequstRAM[i]})
nfvManager.add_vnf_into_pool(vnfEm_template)
设置VNF间虚拟链路资源占用:
VnfManager对象提供了set_vnf_resource_info方法,用于设置VNF间的虚拟链路资源占用信息。该方法需要三个参数,前两个参数为VNF的ID,第三个参数为资源占用信息。资源占用信息是一个字典,包含资源类型和占用量两个元素,资源类型默认支持单位为MB的带宽,具体取决于想要模拟的网络的资源类型。
vnfRequstBAND = NumberGen.getMatrix(vnfTypeNum,**{'type':'symmetric','dtype':'int','low':10,'high':100})
for i in range(vnfTypeNum):
for j in range(vnfTypeNum):
nfvManager.add_vnf_service_into_pool(i,j,**{"band":vnfRequstBAND[i,j]})
保存VNF管理器:为了方便后续的仿真,可以将
VnfManager对象保存为一个pickle文件进行固化,即无需每次都重新构建该对象,该方法适用于构建随机网络拓扑的场景并测试不同算法的性能时,进行变量控制。
with open(f"{nfvManager.__class__.__name__}_{SIMULATION_ID}.pkl", "wb") as file:
pickle.dump(nfvManager, file)
步骤三:定义SFC拓扑
SFC拓扑是指部署在基底网络上的服务流,它由多个服务节点和服务链路组成。每个服务节点都代表一个具体的服务,该示例中我们进行的是基于数值的仿真,因此该服务为虚拟的,仅仅体现在对基底网络中物理节点设置的资源占用。
ID:一个整数列表,用于标记SFC的ID。该值将用来标记每个SFC的唯一性,且该列表的长度应该与服务链路的数量相匹配。在仿真结束后生成的日志记录中,会包含每个SFC的ID,方便后续的分析。需要注意的是,SFC的ID不能重复,否则会导致仿真结果的错误。
sfcNum = 300
sfcIdList = [i for i in range(sfcNum)]
生命周期:一个以SFC ID为索引的字典,用于描述SFC的生命周期。字典的键为SFC的ID,值为一个列表,包含两个元素,分别为SFC的建立时间和终止时间。该值以秒为单位,且生命周期的终止时间应该大于等于建立时间。MiniSFC会根据该信息来自动生成事件,调度每一个SFC的部署和终止,并在最后一个生命周期终止时停止仿真。需要注意的是,该字典的键需要与SFC ID列表中的元素严格一一对应。MiniSFC提供了
NumberGen模块支持按照到达时间的分布模型来生成随机数,用于生成SFC的生命周期。
sfcArriveTime = np.cumsum(NumberGen.getVector(sfcNum,**{'distribution':'possion','dtype':'float','lam':0.55,'reciprocal':True}))
sfcLifeLength = NumberGen.getVector(sfcNum,**{'distribution':'uniform','dtype':'float','low':5,'high':60})
sfcLifeTimeDict = {sfcIdList[i]:[sfcArriveTime[i],sfcArriveTime[i]+sfcLifeLength[i]]
for i in range(sfcNum)}
端点:一个以SFC ID为索引的字典,用于描述SFC的端点。端点的设置基于这样一种假设,即用户对其请求服务的接入接出点是基于用户与网络设施的相对物理位置的,当由于网络拓扑的变化而导致服务的接入接出点发生变化时,用户应当重新请求服务(此处是当前版本V2.0的权宜之计,后续版本将设计更符合实际情况的动态设置方法)。字典的键为SFC的ID,值为一个列表,包含SFC的接入接出点对应的基底网络上的物理节点ID。要注意的是,该字典的键需要与SFC ID列表中的元素严格一一对应。
sfcEndPointDict = {sfcIdList[i]:[random.sample(range(topoSize),1)[0],random.sample(range(topoSize),1)[0]] for i in range(sfcNum)}
VNF请求:一个以SFC ID为索引的字典,用于描述SFC的VNF请求。字典的键为SFC的ID,值为一个列表,包含SFC所需的VNF的ID,其中的ID值即为VNF模板池中VNF模板的ID,列表的长度即为SFC所需的VNF数量,由于不同VNF的功能不同,因此该列表中允许出现相同的VNF ID,即使用一个VNF模版分别创建不同的实例进行部署。需要注意的是,该字典的键需要与SFC ID列表中的元素严格一一对应。
sfcVnfNum = NumberGen.getVector(sfcNum,**{'distribution':'uniform','dtype':'int','low':5,'high':10})
sfcVnfRequstDict = {sfcIdList[i]:random.sample(sfcVnfIdList,sfcVnfNum[i]) for i in range(sfcNum)}
服务QoS需求:一个以SFC ID为索引的字典,用于描述SFC的QoS需求。字典的键为SFC的ID,值为一个列表,包含SFC的QoS需求,这里与基底网络中节点之间的传输时延对应,单位为毫秒,该值表示SFC的端到端时延要求。需要注意的是,该字典的键需要与SFC ID列表中的元素严格一一对应。这里我们假设QoS需求与服务的类型相关,参考了5G的三种服务类型(URLLC、mMTC、eMBB)的QoS需求,并在不同的取值范围内随机生成了QoS需求值。
sfcNum_URLLC = int(sfcNum*(2/8))
sfcNum_mMTC = int(sfcNum*(5/8))
sfcNum_eMBB = sfcNum-(sfcNum_URLLC+sfcNum_mMTC)
sfcLatencyRequest_URLLC = NumberGen.getVector(sfcNum_URLLC,**{'distribution':'uniform','dtype':'float','low':0.1,'high':0.150})
sfcLatencyRequest_mMTC = NumberGen.getVector(sfcNum_mMTC,**{'distribution':'uniform','dtype':'float','low':0.1,'high':0.300})
sfcLatencyRequest_eMBB = NumberGen.getVector(sfcNum_eMBB,**{'distribution':'uniform','dtype':'float','low':0.1,'high':0.400})
sfcLatencyRequest = np.concatenate((sfcLatencyRequest_URLLC,sfcLatencyRequest_mMTC,sfcLatencyRequest_eMBB))
sfcQosRequestDict = {sfcIdList[i]:[sfcLatencyRequest[i]] for i in range(sfcNum)}
在这些信息准备好后,就可以构建一个来自于Minisfc的ServiceTopo对象,该对象包含了所有SFC拓扑信息。
from minisfc.topo import ServiceTopo
serviceTopo = ServiceTopo(sfcIdList,sfcLifeTimeDict,endPointDict,vnfRequstDict,qosRequesDict)
为了方便后续的仿真,可以将该ServiceTopo对象保存为一个pickle文件进行固化,即无需每次都重新构建该对象,该方法适用于构建随机网络拓扑的场景并测试不同算法的性能时,进行变量控制。
with open(f"{serviceTopo.__class__.__name__}_{SIMULATION_ID}.pkl", "wb") as file:
pickle.dump(serviceTopo, file)
步骤四:定义SFC部署求解器
MiniSFC提供了多种SFC部署求解器,用于求解SFC在基底网络上的部署方案。在仿真之前,需要选择一个部署求解器,该求解器可以来自于Minisfc的SfcSolver类例如RandomSolver、GreedySolver等,也可以来自于用户集成了Minisfc的SfcSolver类后实现的自定义求解器,例如PsoSolver。
SfcSolver对象的实例化需要两个参数,第一个参数为SubstrateTopo对象,第二个参数为ServiceTopo对象,这两个对象分别代表了基底网络拓扑和SFC拓扑,可用于求解器的初始化。因此我们默认求解器具备未来网络发生事件的全部信息,因此可用于基于学习类的预测算法。当然如果用户希望实现一个完全基于突发事件的求解器,则可以忽略掉这两个参数,而是仅根据事件发生时的信息进行计算。
from minisfc.solver import RandomSolver, GreedySolver
from custom.psoSolver import PsoSolver
sfcSolver = PsoSolver(substrateTopo,serviceTopo)
步骤五:定义MiniSFC仿真器
MiniSFC提供了Minisfc类来进行仿真,该类包含了仿真的主要逻辑,包括事件驱动、事件处理、事件调度、仿真结果记录等。
Minisfc对象的实例化需要四个参数,第一个参数为SubstrateTopo对象,第二个参数为ServiceTopo对象,第三个参数为VnfManager对象,第四个参数为SfcSolver对象,即为前面定义的准备好的对象。
from minisfc.net import Minisfc
net = Minisfc(substrateTopo,serviceTopo,nfvManager,sfcSolver)
开始仿真
在仿真开始之前,允许用户自定义仿真结果的保存路径或文件名,默认路径为运行脚本所在的当前目录。
MiniSFC默认提供了两种仿真结果记录方式,一种是基于事件的记录,即记录每一个事件的发生时间、事件类型、事件相关的对象、事件相关的属性等信息,该方式可以用于算法性能以及执行结果的分析。另一种是基于每个物理节点的记录,即记录每一个事件发生时间时,每个物理节点的CPU、内存占用情况,该方式可以用于对比不同算法对资源的分配情况。用户可以根据自己的需求设计新的仿真结果记录条目,只需继承TraceResult或TraceNfvi类,并参照其在MANO中的调用方式,重写所需方法即可。
TraceResultFile = f'{TRACE_RESULT.__class__.__name__}_{sfcSolver.__class__.__name__}_{SIMULATION_ID}.csv'
TRACE_RESULT.set(TraceResultFile)
TraceNfviFile = f'{TRACE_NFVI.__class__.__name__}_{sfcSolver.__class__.__name__}_{SIMULATION_ID}.csv'
TRACE_NFVI.set(TraceNfviFile)
上述工作完成后,就可以启动仿真,该过程会自动生成事件并进行调度,直到所有SFC的生命周期终止。net.stop()在基于数值的仿真中不重要,因为在所有的事件都处理完后,仿真会自动停止。因此可以不用调用该方法。(为了体现仿真的完整性和规范性,这里还是调用了该方法)但是在基于容器的模拟仿真中,该方法是必须的,因为需要该方法释放仿真过程中所占用的资源并退出Containernet仿真环境,避免对下次仿真造成影响。
net.start()
net.stop()
如果使用示例中的默认脚本,则运行如下命令:
cd minisfc/examples/simple_dynamictopo
python simple_dynamictopo.py
如果使用了Anaconda环境(例如命名为minisfc的开发环境),则运行如下命令:
cd minisfc/examples/simple_dynamictopo
conda activate minisfc
python simple_dynamictopo.py
仿真过程
在仿真运行过程中,会在执行该脚本中的终端创建一个基于tqdm的进度条,显示仿真的进度。该进度条会显示当前仿真时间、当前仿真事件等信息。可用于观察仿真的运行情况,以及当仿真突然中断时,可以根据进度条信息来进行调试。
结果分析
当仿真结束后,脚本所在的工作目录下会生成两个日志记录文件:
TraceResult_{SolverName}_{SimulationID}.csv:该日志文件的记录条目为Event,Time,SfcId,Result,Resource,Vnffgs,Solution,ReasonEvent:事件类型,参考NS3的设置,这里使用了+来表示SFC请求的到来,-来表示SFC生命周期终止,t来表示基底网络拓扑发生变化。Time:事件发生的时间,单位为秒。SfcId:事件相关的SFC的ID。Result:事件的结果,True表示SFC部署成功,False表示SFC部署失败。Resource:事件发生时全网的剩余资源情况,格式为[cpu:mem:band],分别表示CPU、内存、带宽的剩余资源。Vnffgs:事件发生时在网运行的SFC情况,格式为[SFC_ID]。Solution:事件的部署方案,格式为vnffg1:node1,vnffg2:node2,vnffg3:node3,即该事件部署的SFC上的每个VNF部署在哪个基底网络节点上。Reason:事件的原因,当事件类型为-或t时,该字段记录了SFC的终止原因(例如超时、资源不足等)。
TraceNfvi_{SolverName}_{SimulationID}.csv:该日志文件的记录条目为Event,Time,NVFI_0_cpu,NVFI_0_ram,NVFI_0_vnfs,NVFI_1_cpu...Event:事件类型,参考NS3的设置,这里使用了+来表示SFC请求的到来,-来表示SFC生命周期终止,t来表示基底网络拓扑发生变化。Time:事件发生的时间,单位为秒。NVFI_i_cpu:第i个节点的CPU占用情况,单位为核数。NVFI_i_ram:第i个节点的内存占用情况,单位为MB。NVFI_i_vnfs:第i个节点上运行的VNF的ID列表。
用户可以根据自己的需求对日志文件进行分析,例如绘制仿真结果图表、分析SFC部署失败的原因、分析资源的分配情况等。
MiniSFC提供了一个简易的分析模块DataAnalysis,可以帮助用户快速分析日志文件,在每次仿真结束后,该模块会自动打印一行文字输出SFC部署成功率等信息,用户可以根据该信息快速判断算法的性能。
from minisfc.util import DataAnalysis
DataAnalysis.getResult(TraceResultFile)
批量仿真
如果需要批量运行多个仿真,则可以参考脚本simple_sagintopo_gen.py与simple_sagintopo_load.py的做法,将仿真场景的生成与仿真的加载分离,然后自定义循环体读取生成的场景文件进行仿真。这里给出一个通过循环体修改SFC个数批量生成场景后进行仿真并分别分析结果后绘制的算法对比图如下:
